作者: 兆光科技 發(fā)布時間: 2024/08/09 點擊: 600次
ChatGPT火了以後(hòu),用法是真多。
有人拿來尋求人生建議,有人幹脆當搜索引擎用,還(hái)有人拿來寫論文。
論文...可不興寫啊。
美國(guó)部分大學(xué)已經(jīng)明令禁止學(xué)生使用ChatGPT寫作業,還(hái)開(kāi)發(fā)了一堆軟件來鑒别,判斷學(xué)生上交的論文是不是GPT生成(chéng)的。
這(zhè)裡(lǐ)就出了個問題。
有人論文本來就寫的爛,判斷文本的AI以爲是同行寫的。
更搞的是,中國(guó)人寫的英文論文被(bèi)AI判斷爲AI生成(chéng)的概率高達61%。

這(zhè)....這(zhè)這(zhè)什麼(me)意思?氣抖冷!
目前,生成(chéng)式語言模型發(fā)展迅速,确實給數字通信帶來了巨大進(jìn)步。
但濫用真的不少。
雖說研究人員已經(jīng)提出了不少檢測方法來區分AI和人類生成(chéng)的内容,但這(zhè)些檢測方法的公平性和穩定性仍然亟待提高。
爲此,研究人員使用母語爲英語和母語不爲英語的作者寫的東西評估了幾個廣泛使用的GPT檢測器的性能(néng)。
研究結果顯示,這(zhè)些檢測器始終將(jiāng)非母語者寫作的樣(yàng)本錯誤地判定爲AI生成(chéng)的,而母語寫作樣(yàng)本則基本能(néng)被(bèi)準确地識别。
此外,研究人員還(hái)證明了,用一些簡單的策略就可以減輕這(zhè)種(zhǒng)偏見,還(hái)能(néng)有效地繞過(guò)GPT檢測器。
這(zhè)說明什麼(me)?這(zhè)說明GPT檢測器就看不上語言表達水平不咋地的作者,多叫(jiào)人生氣。
不禁聯想到那款判斷AI還(hái)是真人的遊戲,如果對(duì)面(miàn)是真人但你猜是AI,系統就會說,「對(duì)方可能(néng)會覺得你冒犯了。」
研究人員從一個中國(guó)的教育論壇上獲取了91篇托福作文,又從美國(guó)Hewlett基金會的數據集中摘取了88篇美國(guó)八年級學(xué)生寫的作文,用來檢測7個被(bèi)大量使用的GPT檢測器。

圖表中的百分比表示「誤判」的比例。即,是由人寫的,但檢測軟件認爲是AI生成(chéng)的。
可以看到數據非常懸殊。
七個檢測器中,美國(guó)八年級學(xué)生寫的作文被(bèi)誤判的概率最高才12%,還(hái)有兩(liǎng)個零誤判的GPT。
中國(guó)論壇上的托福作文被(bèi)誤判的概率基本全部過(guò)半,最高誤判概率可達76%。
91篇托福作文中的18篇被(bèi)所有7個GPT檢測器一緻認爲是AI生成(chéng)的,而91篇中有89篇,都(dōu)至少被(bèi)一個GPT檢測器誤判。
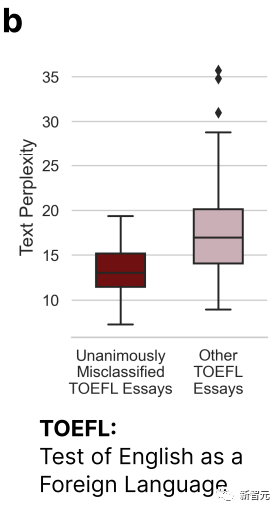
從上圖中我們可以看出,被(bèi)所有7個GPT誤判的托福作文在複雜度(Complexity)上明顯低于其它論文。
這(zhè)就印證了開(kāi)頭的那個結論——GPT檢測器會對(duì)那些語言表達能(néng)力有限的作者有一定偏見。
因此,研究人員認爲,GPT檢測器應該多看點兒非母語者寫的文章,樣(yàng)本多了,才能(néng)消除偏見。
接下來,研究人員把非母語者寫的托福作文扔到了ChatGPT裡(lǐ),豐富一下語言,模仿母語者的用詞習慣。
同時作爲對(duì)照組,把美國(guó)八年級小孩兒寫的作文也扔到了ChatGPT裡(lǐ),把語言簡化了一下,模仿非母語者的寫作特點。下圖就是修正後(hòu)的新判定結果。

我們可以發(fā)現,情況來了個大掉個兒,豐富了語言的托福作文錯判率直線下降,低至3%,最高也不過(guò)19%。不像之前基本全部過(guò)半的錯判率。
與之相反,八年級小孩兒寫的作文的錯判率直線上升,甚至還(hái)有一個GPT檢測器的錯判率高達99%,基本全錯。
因爲,文章複雜度這(zhè)個變量出現了變化。

這(zhè)裡(lǐ)研究人員就得出了一個結論,非母語者寫的東西不地道(dào),複雜度低,容易被(bèi)錯判。
這(zhè)也就導向(xiàng)了一個技術問題,同時也是一個價值問題。以複雜度來判定AI還(hái)是人類是作者,是否合理、全面(miàn)、嚴謹。
結果顯然不是。
以複雜度爲判斷标準的情況下,非母語者吃了大虧,因爲,他們是非母語者(廢話)。
研究者認爲,加強語言多樣(yàng)性不僅可以減輕對(duì)非母語者的偏見,還(hái)能(néng)讓GPT生成(chéng)的内容繞過(guò)GPT檢測器。
爲了證明這(zhè)個觀點,研究人員選取了2022-2023年間美國(guó)大學(xué)申請的入學(xué)論文題目,輸入到ChatGPT-3.5裡(lǐ),一共生成(chéng)了31篇假論文。
GPT檢測器一開(kāi)始還(hái)挺有效,但是第二輪就不行了。這(zhè)是因爲,在第二輪中,研究人員把這(zhè)些論文又扔到ChatGPT裡(lǐ)潤色了一下,用一些文學(xué)性的語言提升了文本質量。
這(zhè)樣(yàng)一來,GPT檢測器的準确度就從100%直降到了0%。如下圖:
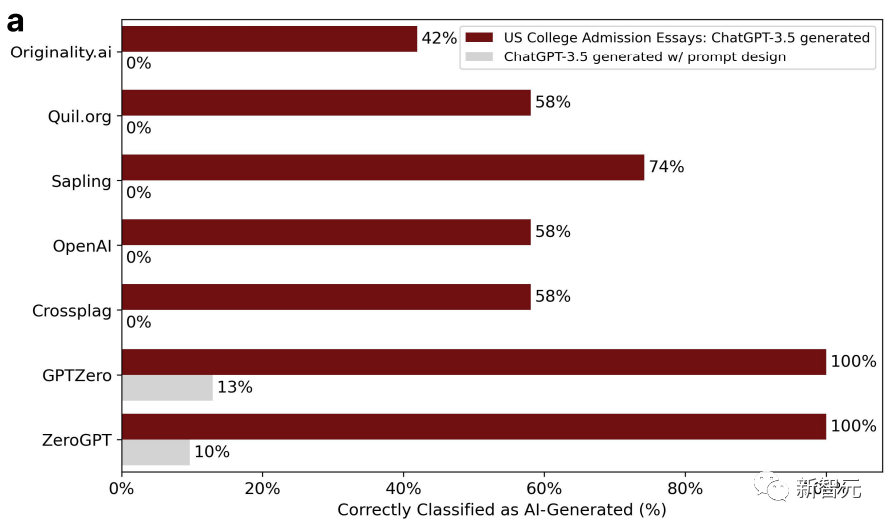
經(jīng)過(guò)潤色的文章複雜度相應也上升了。

與此同時,研究人員又用了斯坦福大學(xué)145個期末項目報告的題目,讓ChatGPT生成(chéng)摘要。

摘要經(jīng)過(guò)潤色以後(hòu),檢測器判斷的準确性繼續下降。
研究者再次得出結論,潤色過(guò)的文章很容易被(bèi)誤判,都(dōu)是AI生成(chéng)的,兩(liǎng)輪就是比一輪強。
言而總之,總而言之,各種(zhǒng)GPT檢測器好(hǎo)像還(hái)是沒(méi)能(néng)抓住AI生成(chéng)和人類寫作之間最本質的區别。
人的寫作也分三六九等,僅靠複雜度判斷,不甚合理。
抛開(kāi)偏見因素不談,技術本身也亟待改進(jìn)。
标簽: ChatGPT
版權申明:本站文章部分自網絡,如有侵權,請聯系:hezuo@lyzg168.com
特别注意:本站所有轉載文章言論不代表本站觀點,本站所提供的攝影照片,插畫,設計作品,如需使用,請與原作者聯系,版權歸原作者所有
輸入您的聯系信息,我們將(jiāng)盡快和你取得聯系!
Tel:15137991270
企業QQ:210603461
Emile:hezuo@lyzg168.com
地址:洛陽市西工區王城大道(dào)221号富雅東方B座1711室
網站:https://www.lyzg168.com

我們的微信
關注兆光,了解我們的服務與最新資訊。
Copyright © 2018-2019 洛陽霆雲網絡科技有限公司
