作者: 兆光科技 發(fā)布時間: 2024/08/08 點擊: 764次
甚至誕生了相應文學(xué)
沒(méi)想到時至今日,ChatGPT竟還(hái)會犯低級錯誤?
吳恩達大神最新開(kāi)課就指出來了:
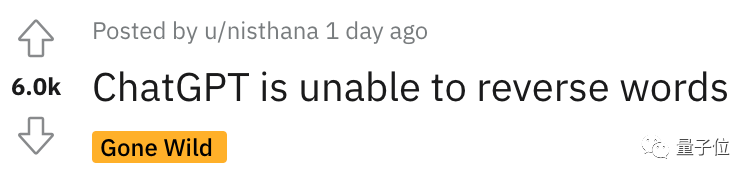
ChatGPT不會反轉單詞!
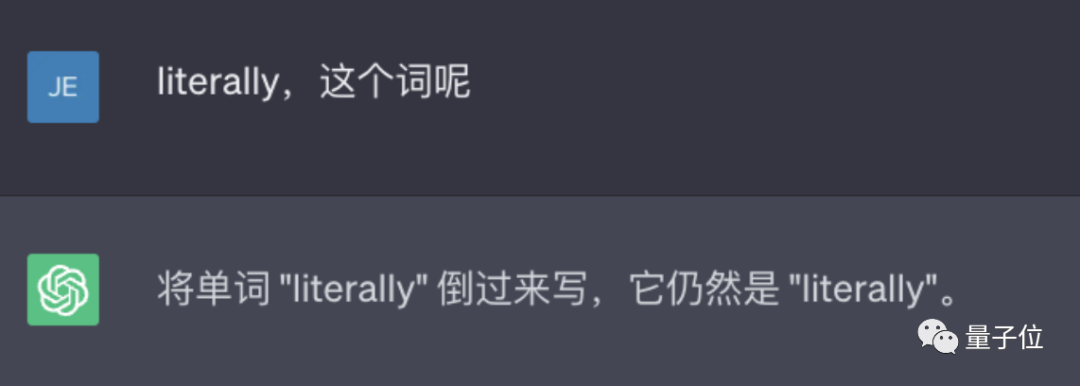
比如讓它反轉下lollipop這(zhè)個詞,輸出是pilollol,完全混亂。

哦豁,這(zhè)确實有點大跌眼鏡啊。
以至于聽課網友在Reddit上發(fā)帖後(hòu),立馬引來大量圍觀,帖子熱度火速沖到6k。
而且這(zhè)不是偶然bug,網友們發(fā)現ChatGPT确實無法完成(chéng)這(zhè)個任務,我們親測結果也同樣(yàng)如此。

△
甚至包括Bard、Bing、文心一言在内等一衆産品都(dōu)不行。
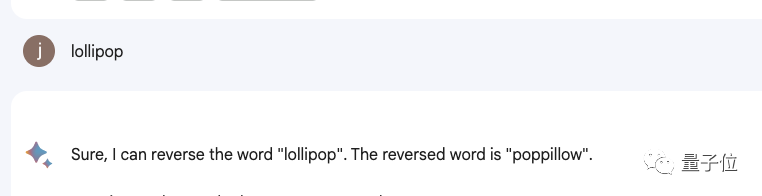
△實測Bard

△
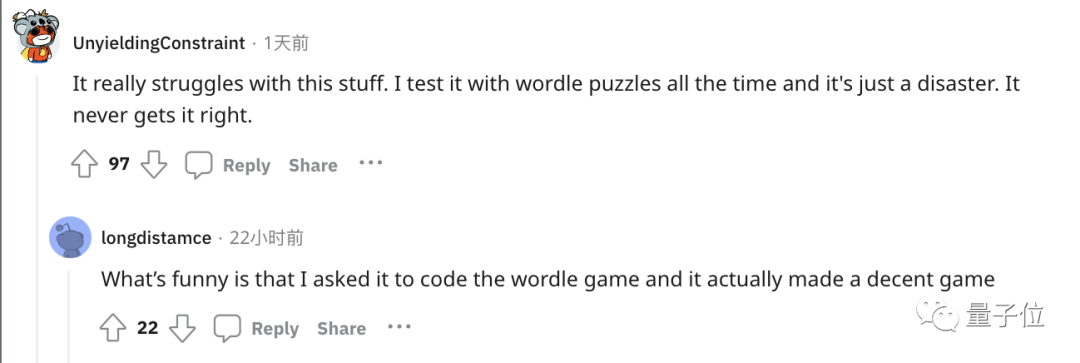
還(hái)有人緊跟著(zhe)吐槽, ChatGPT在處理這(zhè)些簡單的單詞任務就是很糟糕。
比如玩此前曾爆火的文字遊戲Wordle簡直就是一場災難,從來沒(méi)有做對(duì)過(guò)。
诶?這(zhè)到底是爲啥?
之所以有這(zhè)樣(yàng)的現象,關鍵在于token。token是文本中最常見的字符序列,而大模型都(dōu)是用token來處理文本。
它可以是整個單詞,也可以是單詞一個片段。大模型了解這(zhè)些token之間的統計關系,并且擅長(cháng)生成(chéng)下一個token。
因此在處理單詞反轉這(zhè)個小任務時,它可能(néng)隻是將(jiāng)每個token翻轉過(guò)來,而不是字母。

這(zhè)點放在中文語境下體現就更爲明顯:一個詞是一個token,也可能(néng)是一個字是一個token。

針對(duì)開(kāi)頭的例子,有人嘗試理解了下ChatGPT的推理過(guò)程。
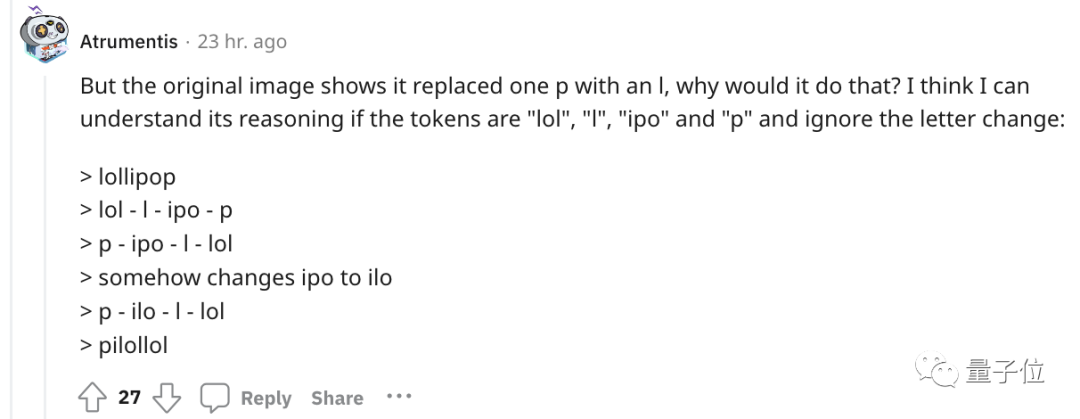
爲了更直觀的了解,OpenAI甚至還(hái)出了個GPT-3的Tokenizer。
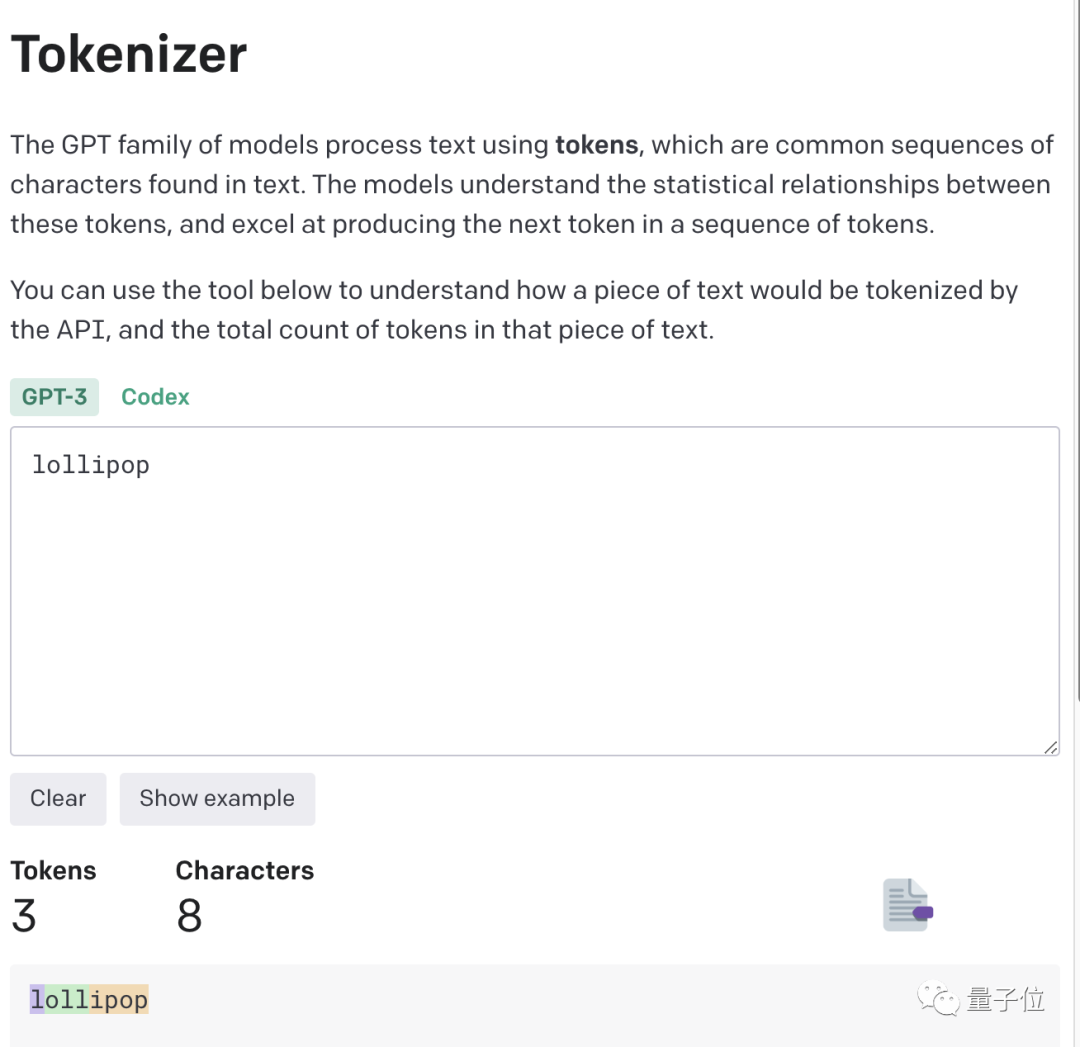
比如像lollipop這(zhè)個詞,GPT-3會將(jiāng)其理解成(chéng)I、oll、ipop這(zhè)三個部分。
根據經(jīng)驗總結,也就誕生出這(zhè)樣(yàng)一些不成(chéng)文法則。
1個token≈4個英文字符≈四分之三個詞;
100個token≈75個單詞;
1-2句話≈30個token;
一段話≈100個token,1500個單詞≈2048個token;
單詞如何劃分還(hái)取決于語言。此前有人統計過(guò),中文要用的token數是英文數量的1.2到2.7倍。
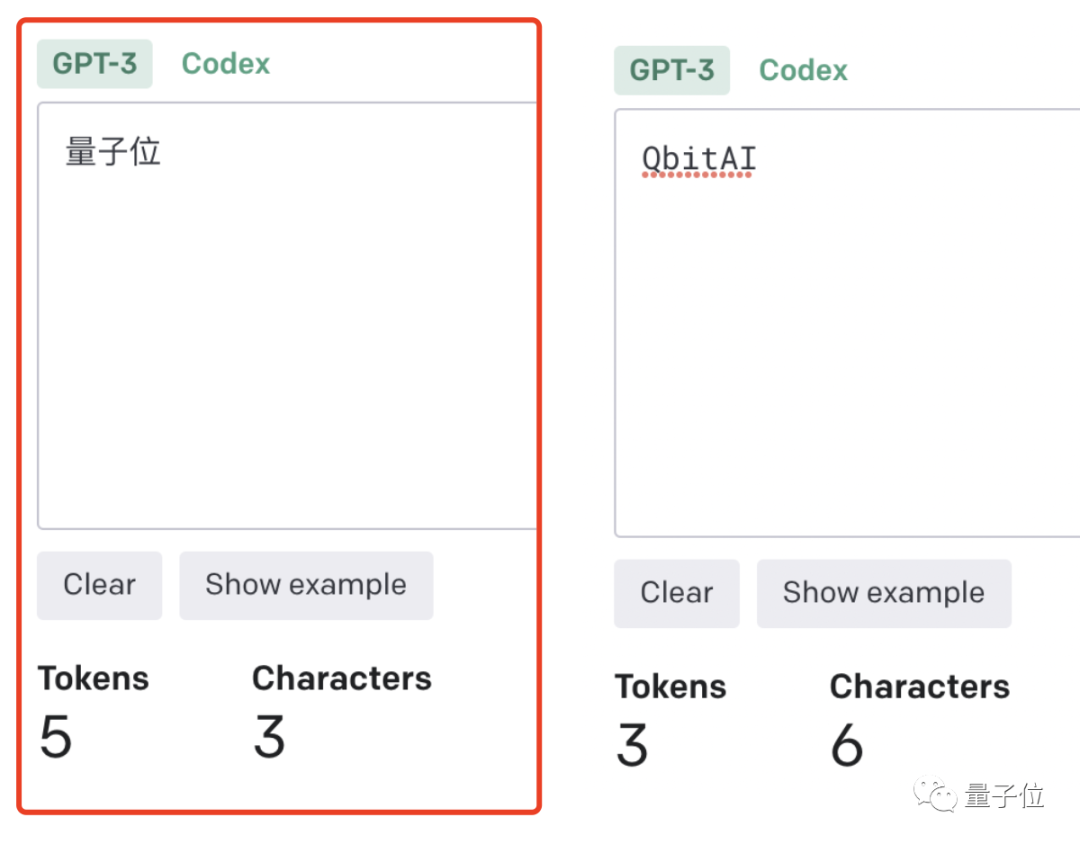
token-to-char(token到單詞)比例越高,處理成(chéng)本也就越高。因此處理中文tokenize要比英文更貴。
可以這(zhè)樣(yàng)理解,token是大模型認識理解人類現實世界的方式。它非常簡單,還(hái)能(néng)大大降低内存和時間複雜度。
但將(jiāng)單詞token化存在一個問題,就會使模型很難學(xué)習到有意義的輸入表示,最直觀的表示就是不能(néng)理解單詞的含義。
當時Transformers有做過(guò)相應優化,比如一個複雜、不常見的單詞分爲一個有意義的token和一個獨立token。
就像annoyingly就被(bèi)分成(chéng)“annoying”和“ly”,前者保留了其語義,後(hòu)者則是頻繁出現。
這(zhè)也成(chéng)就了如今ChatGPT及其他大模型産品的驚豔效果,能(néng)很好(hǎo)地理解人類的語言。
至于無法處理單詞反轉這(zhè)樣(yàng)一個小任務,自然也有解決之道(dào)。
最簡單直接的,就是你先自己把單詞給分開(kāi)喽~

或者也可以讓ChatGPT一步一步來,先tokenize每個字母。

又或者讓它寫一個反轉字母的程序,然後(hòu)程序的結果對(duì)了。(狗頭)

不過(guò)也可以使用GPT-4,實測沒(méi)有這(zhè)樣(yàng)的問題。

△
總之,token就是AI理解自然語言的基石。
而作爲AI理解人類自然語言的橋梁,token的重要性也越來越明顯。
它已經(jīng)成(chéng)爲AI模型性能(néng)優劣的關鍵決定因素,還(hái)是大模型的計費标準。
正如前文所言,token能(néng)方便模型捕捉到更細粒度的語義信息,如詞義、詞序、語法結構等。其順序、位置在序列建模任務(如語言建模、機器翻譯、文本生成(chéng)等)中至關重要。
模型隻有在準确了解每個token在序列中的位置和上下文情況,才能(néng)更好(hǎo)正确預測内容,給出合理輸出。
因此,token的質量、數量對(duì)模型效果有直接影響。
今年開(kāi)始,越來越多大模型發(fā)布時,都(dōu)會著(zhe)重強調token數量,比如谷歌PaLM 2曝光細節中提到,它訓練用到了3.6萬億個token。
以及很多行業内大佬也紛紛表示,token真的很關鍵!
今年從特斯拉跳槽到OpenAI的AI科學(xué)家安德烈·卡帕斯(Andrej Karpathy)就曾在演講中表示:
更多token能(néng)讓模型更好(hǎo)思考。

而且他強調,模型的性能(néng)并不隻由參數規模來決定。
比如LLaMA的參數規模遠小于GPT-3(65B vs 175B),但由于它用更多token進(jìn)行訓練(1.4T vs 300B),所以LLaMA更強大。
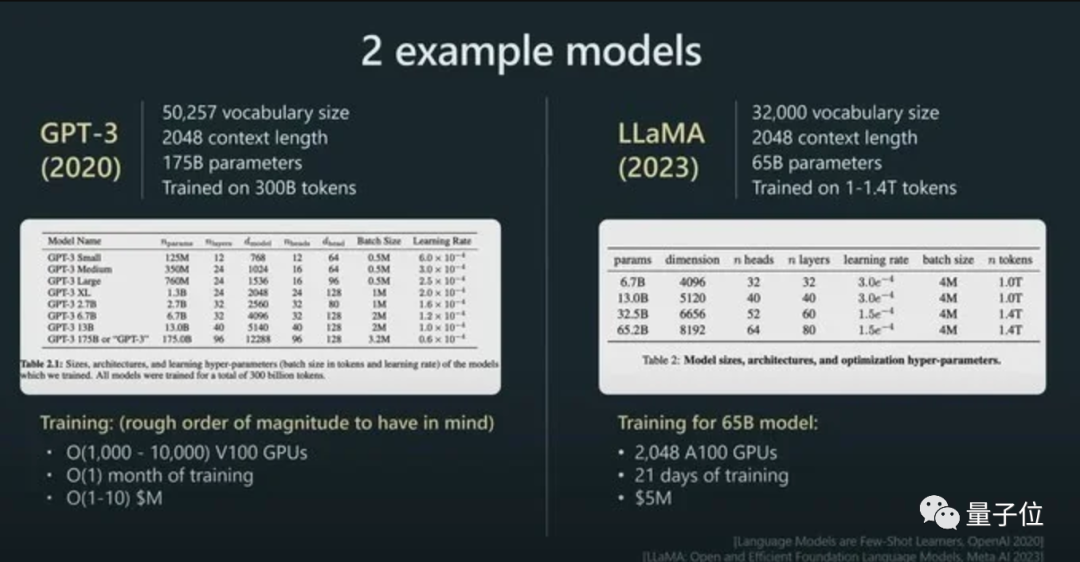
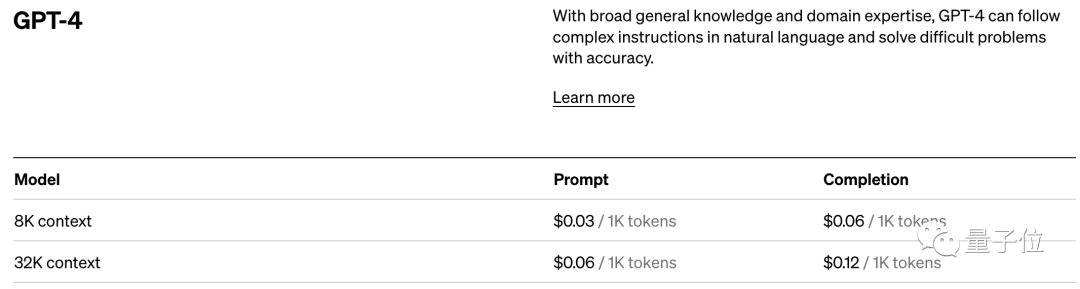
而憑借著(zhe)對(duì)模型性能(néng)的直接影響,token還(hái)是AI模型的計費标準。
以OpenAI的定價标準爲例,他們以1K個token爲單位進(jìn)行計費,不同模型、不同類型的token價格不同。
總之,踏進(jìn)AI大模型領域的大門後(hòu),就會發(fā)現token是繞不開(kāi)的知識點。
嗯,甚至衍生出了token文學(xué)……
不過(guò)值得一提的是,token在中文世界裡(lǐ)到底該翻譯成(chéng)啥,現在還(hái)沒(méi)有完全定下來。
直譯“令牌”總是有點怪怪的。
GPT-4覺得叫(jiào)“詞元”或“标記”比較好(hǎo),你覺得呢?
标簽: AI
版權申明:本站文章部分自網絡,如有侵權,請聯系:hezuo@lyzg168.com
特别注意:本站所有轉載文章言論不代表本站觀點,本站所提供的攝影照片,插畫,設計作品,如需使用,請與原作者聯系,版權歸原作者所有
輸入您的聯系信息,我們將(jiāng)盡快和你取得聯系!
Tel:15137991270
企業QQ:210603461
Emile:hezuo@lyzg168.com
地址:洛陽市西工區王城大道(dào)221号富雅東方B座1711室
網站:https://www.lyzg168.com

我們的微信
關注兆光,了解我們的服務與最新資訊。
Copyright © 2018-2019 洛陽霆雲網絡科技有限公司
