作者: 兆光科技 發(fā)布時間: 2024/08/08 點擊: 758次
大模型中間件是基于AI應用與大模型之間的中間層基礎軟件
2022年底,OpenAI基于大語言模型發(fā)布了聊天應用ChatGPT,推出僅一個月活躍用戶破億,吸引全球範圍的廣泛關注。ChatGPT的出現將(jiāng)人工智能(néng)推向(xiàng)全球關注的中心舞台,大語言模型帶動的新一輪人工智能(néng)浪潮,正以前所未有的速度席卷全球。據統計,目前全球大型語言模型相關的創業公司已超過(guò)200家,投資總額達到70億美元。
TechCrunch的數據顯示,2022年前三個季度全球人工智能(néng)的投資已達到560億美元,創下曆史新高。其中,融資較高的創業公司包括Anthropic、Cohere、AI21 Labs等,這(zhè)些公司的技術都(dōu)建立在大型語言模型的基礎之上。
對(duì)于個人用戶,大語言模型帶來了前所未有的高度個性化體驗。它能(néng)夠與用戶進(jìn)行流暢的對(duì)話,并提供即時且針對(duì)性的回應。借助基于大型語言模型的AI寫作助手,用戶能(néng)夠快速生成(chéng)高質量的文章草稿,其風格與用戶貼合,極大提高了内容創作效率。然而,大模型要在企業側真正落地仍然面(miàn)臨很大挑戰,總結爲下面(miàn)四個方面(miàn):
大模型專業深度不夠,數據更新不及時,缺乏與真實世界的連接。例如,在法律政策解讀、電商客服、投資研報等專業領域中,由于大型模型缺乏足夠的專業領域數據,用戶在使用過(guò)程中經(jīng)常會感覺大模型在一本正經(jīng)地“胡說八道(dào)”。
大模型有Token的限制,記憶能(néng)力有限。大家之所以驚豔于ChatGPT流暢絲滑的對(duì)話能(néng)力,有很大一部分原因是其支持多輪對(duì)話。用戶提問時,ChatGPT不但能(néng)理解意圖,而且還(hái)能(néng)夠基于之前的問答做綜合推理。然而,大模型由于Token的限制,隻能(néng)記憶部分的上下文。比如ChatGPT 3.5隻能(néng)記憶4096個Token,無法實現長(cháng)期記憶。
用戶對(duì)于數據安全的擔憂。大模型的出現讓AI成(chéng)爲一種(zhǒng)普惠技術,人人都(dōu)可以基于大模型構建AI的應用。AI技術本身不再是商業壁壘,數據才是。而企業要想利用大模型構建商業,必須將(jiāng)自己的數據全部輸送給大模型,以進(jìn)行推理和表達。如何在數據安全可控的情況下使用大模型技術,成(chéng)爲一個亟待解決的問題。
使用大模型的成(chéng)本問題。目前有兩(liǎng)種(zhǒng)模式可以使用大模型,一是將(jiāng)大模型本地化,用于再訓練形成(chéng)企業專有的模型。二是利用公有雲模型,按照請求的Token數量付費。第一種(zhǒng)方式成(chéng)本極高,大模型由于有數千億的模型參數,光部署計算資源的投資就得上億。重新訓練一次模型也需要近千萬的投入,非常燒錢。這(zhè)對(duì)于一般的中小企業是完全無法承受的。第二種(zhǒng)方式企業構建的AI應用可以按照Token數量付費,雖然無需一次性的大額投入,但成(chéng)本依然不低。以OpenAI爲例,如果對(duì)通用模型進(jìn)行微調(Fine-tuning)後(hòu),每使用1000個token(約600漢字)需要0.12美金。
針對(duì)上述問題,目前主要有三個解決方案:
第一是將(jiāng)大模型部署到企業本地,結合企業私有數據進(jìn)行訓練,打造垂直領域專有模型。
第二是在大模型基礎上進(jìn)行參數微調,改變部分參數,讓其能(néng)夠掌握深度的企業知識。
第三種(zhǒng)是圍繞向(xiàng)量數據庫打造企業的知識庫,基于大模型和企業知識庫再配合Prompt打造企業專屬AI應用。
從實用性和經(jīng)濟性的角度考慮,第三種(zhǒng)是最爲有效的解決方案。該方案大緻實現方式如下所示。
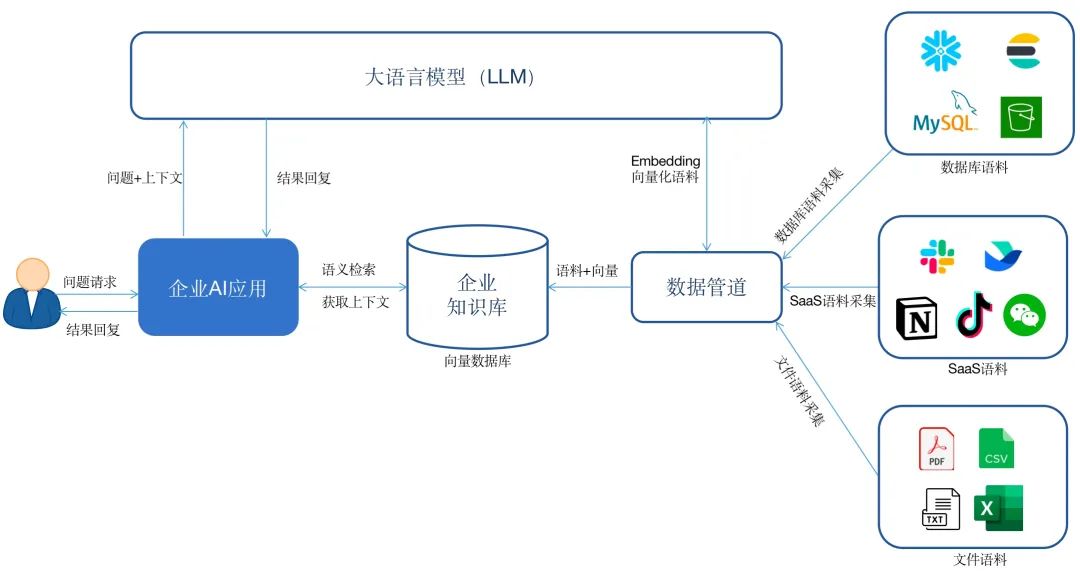
企業首先基于私有數據構建一個知識庫。通過(guò)數據管道(dào)將(jiāng)來自數據庫、SaaS軟件或者雲服務中的數據實時同步到向(xiàng)量數據庫中,形成(chéng)自己的知識庫。
在這(zhè)個過(guò)程中需要調用大模型的Embedding接口,將(jiāng)語料進(jìn)行向(xiàng)量化,然後(hòu)存儲到向(xiàng)量數據庫。當用戶與企業AI應用對(duì)話時,AI應用首先會將(jiāng)用戶的問題在企業知識庫中做語義檢索,然後(hòu)將(jiāng)檢索的相關答案和問題以及配合一定的prompt一并發(fā)給大模型,獲得最終的答案之後(hòu)回複給用戶。
該方案有如下優勢:
充分利用大模型和企業優勢:既可以充分利用企業已有知識,又可以利用大模型強大的表達和推理能(néng)力,二者完美融合。
使AI應用具備長(cháng)期記憶:Token的限制使大模型隻能(néng)有短暫的記憶,無法將(jiāng)企業所有知識全部記住。利用外置的知識庫,可以將(jiāng)企業擁有的海量數據資産全部整合,幫助企業AI應用構建長(cháng)期記憶。
企業數據相對(duì)安全可控:企業可以在本地構建自己的知識庫,避免核心數據資産外洩。
落地成(chéng)本低:通過(guò)該方案落地AI應用,企業不需要投入大量資源建設自己的本地大模型,幫助企業節省動辄千萬的訓練費用。
企業要落地該知識庫方案仍然有一些具體問題需要解決,總結下來主要涉及三個方面(miàn)。
第一方面(miàn)是知識庫的構建。企業需要將(jiāng)存在現有系統中的語料彙總到向(xiàng)量數據庫,形成(chéng)企業自有的知識空間,這(zhè)個過(guò)程涉及數據采集、清洗、轉換和Embedding等工作。語料來源比較多樣(yàng),可能(néng)是一些PDF、CSV等文檔,也可能(néng)需要接入企業現有業務系統涉及比如Mongodb、ElasticSearch等數據庫,或者來自抖音、Shopify、Twitter等第三方應用。在完成(chéng)數據的獲取後(hòu),通常需要對(duì)數據進(jìn)行過(guò)濾或者轉化。這(zhè)個過(guò)程中,從數據源實時地獲取數據非常重要,比如電商機器人需要實時了解用戶下單的情況,政策解讀機器人需要了解最新政策信息。另外,對(duì)于數據Embedding的過(guò)程中涉及到數據的切塊,數據切塊的大小會直接影響到後(hòu)面(miàn)語義搜索的效果,這(zhè)個工作也需要非常專業的NLP工程師才能(néng)做好(hǎo)。
其次是AI應用的集成(chéng)。AI應用需要服務的用戶可能(néng)存在于微信、飛書、Slack或者企業自有的業務系統。如何將(jiāng)AI應用與第三方SaaS軟件進(jìn)行無縫集成(chéng),直接決定用戶的體驗和效果。
第三是數據安全性的問題。這(zhè)個方案沒(méi)有完全解決數據安全性的問題,雖然企業的知識庫存儲在本地,但是由于企業數據向(xiàng)量化的過(guò)程中需要調用公有雲大模型Embedding接口。這(zhè)個過(guò)程需要將(jiāng)企業數據切塊之後(hòu)發(fā)送給大模型,一樣(yàng)有數據安全的隐患。
對(duì)于上述大模型落地問題的解決,大模型中間件是其中的關鍵。
什麼(me)是大模型中間件?大模型中間件是位于AI應用與大模型之間的中間層基礎軟件,它主要解決大模型落地過(guò)程中數據集成(chéng)、應用集成(chéng)、知識庫與大模型融合等問題。
下圖給出了企業AI應用的典型軟件架構,一共分爲大語言模型、向(xiàng)量數據庫、大模型中間件以及AI應用四層。
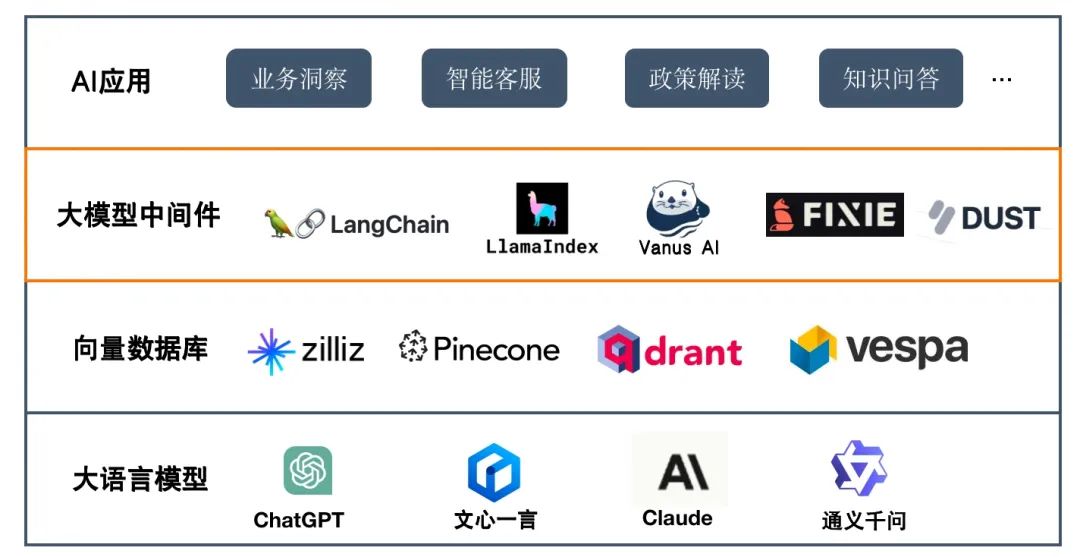
大語言模型爲AI應用提供基礎的語義理解、推理、計算能(néng)力,向(xiàng)量數據庫主要提供企業知識的存儲和語義搜索。而大模型中間件解決大模型落地的最後(hòu)一公裡(lǐ),提供語料的實時采集、數據清洗、過(guò)濾、embedding。同時,爲上層應用提供訪問大模型與知識庫的入口,提供大模型與知識庫的融合、應用部署、應用執行。
自去年ChatGPT發(fā)布以來,短短幾個月内就湧現出了不少新的大模型中間件項目。例如,面(miàn)向(xiàng)AI應用的編程框架Langchain在GitHub上短短幾個月内收獲了超過(guò)4萬個Star。Langchain旨在簡化開(kāi)發(fā)者基于大型語言模型構建AI應用的過(guò)程。它爲開(kāi)發(fā)者提供了多模型訪問、Prompt的封裝、多數據源加載等多種(zhǒng)接口,讓開(kāi)發(fā)者構建AI應用更簡單。Llamaindex是另一個備受關注的開(kāi)源項目,它目标是爲大型模型提供統一的接口來訪問外部數據。比如Llamaindex的Routing爲開(kāi)發(fā)者語義檢索、基于事(shì)實混合查找、訪問總結數據可以提供統一索引。Vanus AI 是一個無代碼構建AI應用的中間件,用戶通過(guò)Vanus AI可以分鍾級構建出生産可用的AI應用。它同時提供了實時知識庫構建、AI應用集成(chéng)、大模型插件等能(néng)力。Fixie是一家初創公司,近期剛剛融資1200萬美金,該公司的目标是構建、部署和管理大型模型代理平台,以更好(hǎo)地響應用戶的意圖。
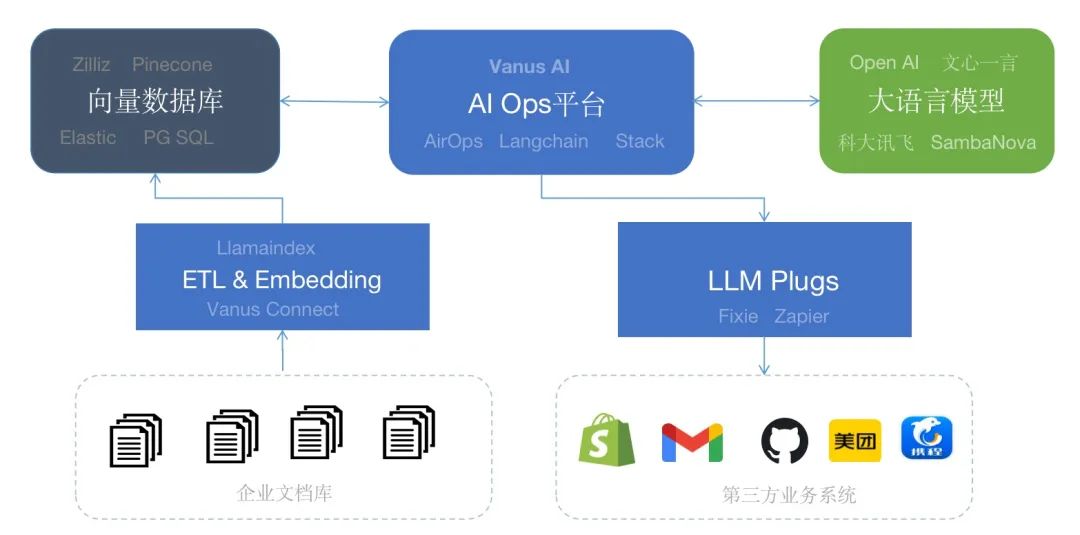
對(duì)近期項目進(jìn)行了梳理,形成(chéng)下圖的AI Stack。企業的私有業務數據通過(guò) Embedding組件轉化成(chéng)向(xiàng)量後(hòu)可以存儲到Milvus、Pinecone等向(xiàng)量數據庫中。目前通過(guò)Llamaindex、Vanus Connect可以批量獲取PDF、CSV等文件并Embedding并存儲到向(xiàng)量數據庫中。AirOps、Vanus AI等AI Ops平台可以連接大模型和企業知識庫幫助用戶一站式構建AI的應用。如果AI應用需要連接第三方的應用執行操作可以通過(guò)Fixie或者Zapier等提供了插件。
标簽: AI
版權申明:本站文章部分自網絡,如有侵權,請聯系:hezuo@lyzg168.com
特别注意:本站所有轉載文章言論不代表本站觀點,本站所提供的攝影照片,插畫,設計作品,如需使用,請與原作者聯系,版權歸原作者所有
輸入您的聯系信息,我們將(jiāng)盡快和你取得聯系!
Tel:15137991270
企業QQ:210603461
Emile:hezuo@lyzg168.com
地址:洛陽市西工區王城大道(dào)221号富雅東方B座1711室
網站:https://www.lyzg168.com

我們的微信
關注兆光,了解我們的服務與最新資訊。
Copyright © 2018-2019 洛陽霆雲網絡科技有限公司
