作者: 兆光科技 發(fā)布時間: 2024/08/09 點擊: 8685次
生成(chéng)式AI正在成(chéng)爲一個新的範式。

内容來源:2023年6月10日,筆記俠舉辦的“Ai新視野,增長(cháng)新勢能(néng)”新商業千人大會。
分享嘉賓:方軍,快知實驗室合夥人&UWEB教育合夥人。
AI
我今天分享的主題是《把握生成(chéng)式AI新範式:趨勢、原理與應用》。
今天我會盡量少談技術但又不可避免要提及不少技術名詞,但我想傳遞的一個關鍵信息與技術無關:
ChatGPT所引領的生成(chéng)式AI浪潮與你有關,你不一定需要自己做大模型或做應用研發(fā),但你一定可以找到某個角度加入這(zhè)一浪潮。我們每個人都(dōu)應該嘗試去理解生成(chéng)式AI的原理和可能(néng)性,然後(hòu)找到一條屬于自己的路。
2022年11月最後(hòu)一天,ChatGPT聊天機器人出現時,我這(zhè)樣(yàng)的熱愛新技術産品的人跑去使用了,但覺得沒(méi)什麼(me)新鮮的。畢竟我們早前用過(guò)GPT-2寫過(guò)文章,也在用GitHub 基于GPT的工具輔助編程。
這(zhè)大概是一個小叠代,是對(duì)話 UI 的嘗試。很顯然,我很快就發(fā)現自己錯了,這(zhè)小小的一步似乎激發(fā)了AI的潛能(néng),并將(jiāng)AI的潛能(néng)帶到數以百萬計的大衆手中。
生成(chéng)式AI正引領一個新的數字化範式,且跟每個人都(dōu)有很強的關系。在我看來,以 GPT 和圖像生成(chéng)爲代表的生成(chéng)式AI 代表著(zhe)第三波數字化浪潮。
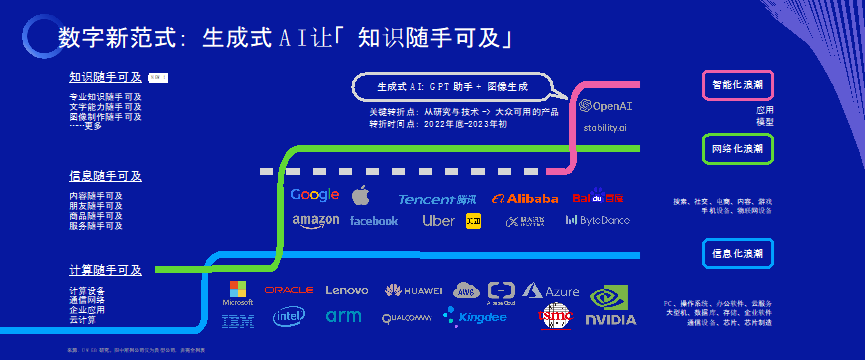
第一波數字化浪潮是讓計算随手可及。這(zhè)是一波延續至今的數字化浪潮,過(guò)去十年大數據、雲計算、企業數字化轉型仍在高速叠代。我們也看到AI的基礎是更強大的計算能(néng)力,比如OpenAI背後(hòu)是微軟Azure雲和英偉達強大的GPU芯片。
第二波數字化浪潮是讓信息随手可及。互聯網和移動互聯網是我們所有人都(dōu)親身參與的變化,比如你随手打開(kāi)APP,就可以看新聞、看視頻、看直播。信息随手可及不僅與資訊有關,它還(hái)改變了做生意或消費的方式,比如我們可以在網上買東西、叫(jiào)網約車、叫(jiào)外賣。
第三波數字化浪潮是讓知識随手可及。ChatGPT、谷歌Bard、百度文心一言、科大訊飛星火等等聊天機器人讓我們能(néng)夠比過(guò)去用搜索引擎更方便地獲得「知識」——有問題我們問AI,而它能(néng)夠針對(duì)性地進(jìn)行回答。我們不會繪畫的人也能(néng)夠用咒語來讓AI繪畫,一下子擁有了新的能(néng)力。經(jīng)訓練的大模型掌握了大量的的知識與能(néng)力,可以爲我們所用。
上個月,ChatGPT的月度用戶量達到了10億,也就是半年時間超過(guò)10億。和它最初以五天時間超過(guò)100萬注冊用戶一樣(yàng),這(zhè)同樣(yàng)創造了互聯網産品用戶增長(cháng)的新記錄。這(zhè)标志生成(chéng)式AI 從研究與技術走向(xiàng)了大衆,成(chéng)爲每個人都(dōu)在日常工作與生活中用的産品。
在這(zhè)個讓知識随手可及的數字化新範式的風起(qǐ)雲湧之時,我們可以做什麼(me)?我們發(fā)現,之前的數字化浪潮都(dōu)呈現造輪子(建)和用輪子(用)兩(liǎng)個分支,建網站或APP大有可爲,但用網站或APP同樣(yàng)大有可爲。
在這(zhè)一波浪潮中,建模型和用模型也均可大有所爲。同時,過(guò)去的數字化經(jīng)驗也告訴我們,抓住先機的兩(liǎng)大關鍵是:
第一,洞悉新技術新産品的原理,了解真正可用的用途。
第二,在理解之後(hòu),勇于嘗試、把握先入優勢。
下面(miàn),我來談談我對(duì)生成(chéng)式AI原理的理解。
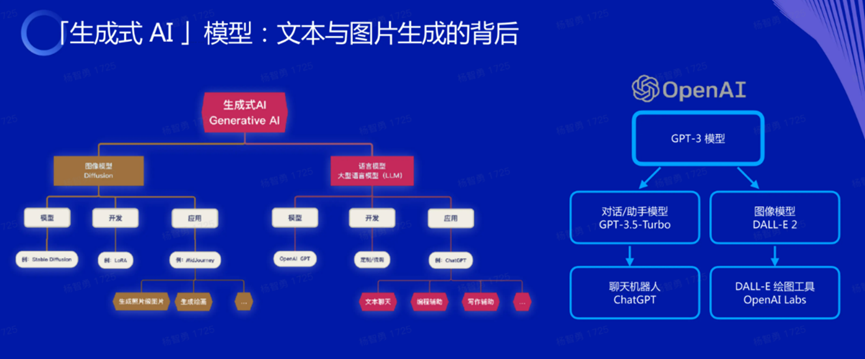
生成(chéng)式AI的兩(liǎng)大基礎功能(néng):文字生成(chéng)與圖像生成(chéng)。同時,兩(liǎng)種(zhǒng)基礎功能(néng)是相似的,我們可以通過(guò)文字「提示語」,來指揮AI去生成(chéng)文、生成(chéng)圖。比如,你是一個服裝公司,你可以將(jiāng)風格用文字描述輸入給它,生成(chéng)商品的展示圖。你可以用提示語指揮AI幫你撰寫賣商品所需的介紹文案。
由文字生成(chéng)文字、由文字生成(chéng)圖像再往前進(jìn),就可以生成(chéng)各種(zhǒng)新東西:把圖像動起(qǐ)來、將(jiāng)文字轉成(chéng)聲音,就可以生成(chéng)視頻。如果生成(chéng)的文字是網站的代碼,再加上圖片、文字,就可以生成(chéng)網站應用。等等。

以OpenAI公司的AI模型進(jìn)化爲例來看很有意思,我們會發(fā)現,由文字生成(chéng)文字的所謂大語言模型、由文字生成(chéng)圖像的圖像模型之間共同的根。
以 GPT-3 爲例,用對(duì)話預料訓練它,形成(chéng)了專門用于對(duì)話的模型,然後(hòu)就有了我們用的聊天機器人。用文本加圖像對(duì)它進(jìn)行訓練,讓它了解文字與圖片之間的關聯,然後(hòu)我們就可用它根據文字描述生成(chéng)圖片。
接下來我們來專門看大語言模型這(zhè)個部分,它是如何擁有知識與能(néng)力的?
首先,研究人員拿海量的文本對(duì)名爲Transformer架構的人工神經(jīng)網絡進(jìn)行預訓練。在預訓練之後(hòu),它掌握關于字詞的概率,它有了這(zhè)樣(yàng)一種(zhǒng)能(néng)力:你說了某個詞,它就能(néng)預測你的下一個詞是什麼(me)。一個詞一個詞、一句話一句話地預測下去,它能(néng)流暢的方式說話了。
雖然它的實質隻是下一個詞預測器,但它的表現的确像掌握了一定的知識、有語言能(néng)力,甚至有推理能(néng)力。
接著(zhe),一個關鍵的轉變就出現了。既然我們給一句話,它可以按照這(zhè)句話所開(kāi)始的模式接著(zhe)說下去。那麼(me),如果我們給定一句問句,它是不是同樣(yàng)可以說下去,但現在它在對(duì)問句進(jìn)行回答了。
我們輸入模型的提示語(Prompt)就有了新的含義,最初它的意思是演員忘詞時的提詞,現在它變成(chéng)了我們提出的問題(請問這(zhè)個問題如何解答)或命令(請幫我解答這(zhè)道(dào)題、請幫我編寫這(zhè)個程序)。提出的問題或發(fā)出的命令,就是我們給AI 模型的指令。
之後(hòu),研究者開(kāi)始著(zhe)力于提升AI模型能(néng)夠更好(hǎo)地對(duì)人類的指令進(jìn)行回應。這(zhè)其中主要的方法是用指令、輸入、輸出所組成(chéng)的指令集數據來對(duì)模型進(jìn)行補充訓練,也叫(jiào)指令微調。
ChatGPT-3.5就是用所謂的人類反饋強化學(xué)習(RLHF)進(jìn)行的微調訓練,它能(néng)更好(hǎo)地響應人類指令,同時也能(néng)夠更好(hǎo)地與人類價值觀對(duì)齊。總而言之,到了這(zhè)個階段之後(hòu),AI 模型就從下一個詞預測器變成(chéng)了能(néng)夠回答問題或指令命令的強大機器。
換個每個人都(dōu)很容易理解的視角再看:公司招聘了聰明的應屆畢業生,他在學(xué)校裡(lǐ)學(xué)到了很多知識。他最初能(néng)做的事(shì)情是,用自己的知識預測下一句話該說什麼(me)。幾個月短暫适應之後(hòu),他能(néng)夠實際參與工作了:你向(xiàng)他提問和給他命令,他回答問題和完成(chéng)任務。
但這(zhè)個優秀的人才還(hái)是不太了解本行業、本企業,我們可以對(duì)他進(jìn)行培訓,當然也包括幹中學(xué),他很快就從大學(xué)畢業生變成(chéng)了本企業的骨幹了。

在2022年底、2023年初,不少人認爲在大語言模型上OpenAI遙遙領先,其他人的追趕需要時間。但2023年3月之後(hòu),人們的看法變了,原因在于,開(kāi)源模型以短短幾個月的時間走完了OpenAI幾年的探索過(guò)程。
以Meta公司開(kāi)源的 Llama模型爲例,它2月底開(kāi)源,3月斯坦福大學(xué)的研究人員基于它微調出 Alpaca模型,之後(hòu)一個大學(xué)與企業界聯合團隊進(jìn)一步微調出對(duì)話模型Vicuna(也就是能(néng)像ChatGPT一樣(yàng)對(duì)話),很快,采用人類反饋強化學(xué)習的開(kāi)源模型如Stable Vicuna也出現了。
圍繞著(zhe)Llama,現在有幾百個開(kāi)源模型在進(jìn)行探索。同時,由中國(guó)清華大學(xué)開(kāi)源的ChatGLM模型也有超級活躍的社區,沙特的一家大學(xué)則推出了Falcon模型,與Meta公司開(kāi)源模型不同,這(zhè)個模型可用于商用。
大語言模型等生成(chéng)式AI模型將(jiāng)知識變得随手可及,而在它發(fā)展的過(guò)程中,它本身的知識實際上在過(guò)去幾個月也變得随手可及。
當然,這(zhè)背後(hòu)還(hái)是有很多訣竅的,是衆多研究人員和産業公司在探索的,比如數據管道(dào)、性能(néng)評估、模型安全性等。衆人目前都(dōu)在沿著(zhe)OpenAI公司開(kāi)辟的道(dào)路前進(jìn):通過(guò)人類反饋強化學(xué)習的方法,來讓模型更好(hǎo)地回答人的指令,同時跟人類的價值觀對(duì)齊。
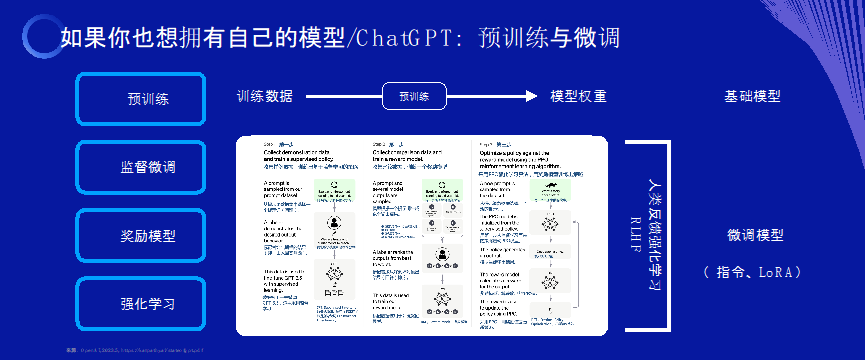
總而言之,GPT模型看著(zhe)很複雜,但總體框架可看成(chéng)包括分兩(liǎng)步:
第一步,進(jìn)行所謂的預訓練及微調,得到一個人工神經(jīng)模型。第二步,將(jiāng)模型的參數部署在服務器上供公衆使用,這(zhè)個過(guò)程通常叫(jiào)提供推理服務,這(zhè)時,我們用戶向(xiàng)它提問、給它指令,得到回答。
如果能(néng)力視角看,我們也看到同樣(yàng)的兩(liǎng)步:第一步,模型在預訓練後(hòu)擁有了比如語言理解、文本生成(chéng)、知識問答、邏輯推理、數學(xué)能(néng)力、代碼能(néng)力、多模态能(néng)力等上遊能(néng)力;第二步,我們將(jiāng)這(zhè)些能(néng)力用于下遊應用,目前主要是問答機器人或應用助手的形式用于比如語言翻譯、輔助寫作、輔助編程、一對(duì)一教育、辦公自動化等場景。
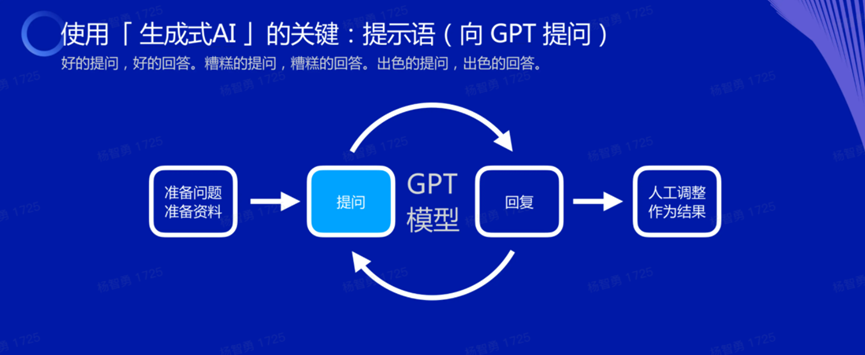
要用好(hǎo)GPT,我們要了解它擅長(cháng)什麼(me),知道(dào)它不擅長(cháng)什麼(me)。另外,我們還(hái)要掌握向(xiàng)它提出問題或發(fā)出命令的能(néng)力,提問能(néng)力越強,我們得到的結果就越好(hǎo)。

很多人都(dōu)已經(jīng)知道(dào)了,GPT 等AI大模型的最大缺是它會是胡說八道(dào),也就是所謂出現幻覺,編造回答。這(zhè)實際上是它的“特性”還(hái)沒(méi)有完全訓練好(hǎo)的問題,這(zhè)是因爲,當我們試圖要求它能(néng)一定程度上“生成(chéng)”新的内容時,我們實際上鼓勵它有在不相關的信息間建立新聯系的能(néng)力。
因此,要用好(hǎo)GPT等AI大模型,關鍵就是要掌握提問的能(néng)力——能(néng)夠高效地提問引導出盡量好(hǎo)的答案,同時提問者又要對(duì)答案的優劣好(hǎo)壞有判斷力。想真正用好(hǎo)GPT,最關鍵的是掌握向(xiàng)它提問的技巧。
比如,你跟它說,幫我寫篇關于故宮600年的文章,對(duì)不起(qǐ),它寫不好(hǎo),因爲你根本沒(méi)有觀點與信息給它。但如果你跟它說,我的公司的情況是這(zhè)樣(yàng),我的産品是這(zhè)樣(yàng),你幫我寫一個産品介紹,他就能(néng)夠幫你寫出來。
1.與大模型打交道(dào):提示語
向(xiàng)AI提問的基本技巧是,你要給它盡可能(néng)多的信息,同時就它的回答進(jìn)行反饋、調整,多次循環叠代後(hòu),你可能(néng)可以得到你想要的回答。在我認爲,提問分爲3個層次:
第一層次正确的提問,懂得提問3要素:詳盡的背景信息、具體的問題描述、清晰的解答要求。
第二層次進(jìn)階的提問,給它少量樣(yàng)本提示、調整提示語重複提問、拆解任務分步提問。
第三層次高階的提問,外挂知識庫、與其他工具聯合使用、多輪交互完成(chéng)複雜任務。
2.運用場景
具體來說,我們可以讓GPT在哪些場景幫助我們呢?
① 頭腦風暴會
比如,很多公司會花大量時間來開(kāi)頭腦風暴會,用好(hǎo)GPT可以幫助我們節省大量時間。
將(jiāng)GPT用于頭腦風暴會的一種(zhǒng)方式是:不用團隊來開(kāi)會,你讓GPT模仿不同的角色,客戶A、客戶B、公司老闆、具體事(shì)務的執行人,還(hái)可以請它扮演一個專門提反對(duì)意見的角色。這(zhè)時,你一個人就可以變成(chéng)一個團隊,一個人就可以進(jìn)行頭腦風暴。
第二種(zhǒng)方式是,你可以讓團隊一起(qǐ)來頭腦風暴,但讓團隊成(chéng)員每人都(dōu)借助GPT的輔助,每個人帶10個想法來會議現場。過(guò)去,很多人帶不來這(zhè)麼(me)多想法;現在,他可以想一兩(liǎng)個想法,然後(hòu)問GPT,最後(hòu)每個人都(dōu)可以輕松帶很多新想法來了。這(zhè)樣(yàng),可以大幅度提高頭腦風暴會的效率,就跟有人說的,用好(hǎo)GPT,可以幫團隊每次頭腦風暴會節省100個小時。
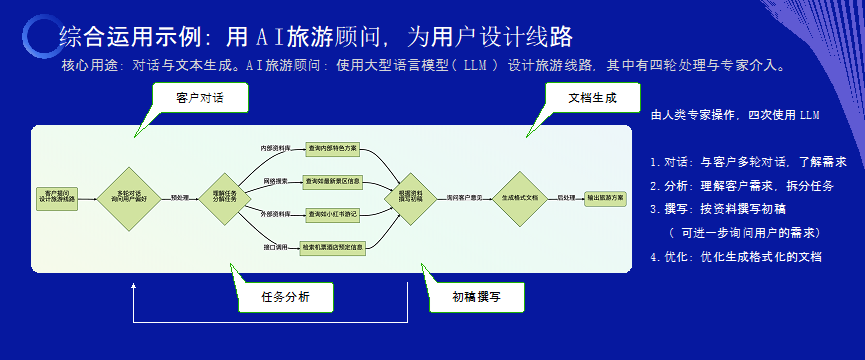
② AI旅遊顧問
我們再來看一個稍微複雜的場景,假設你是一家高端的旅遊服務公司,客戶說,我想要去哪旅遊,我有五六個人,我有什麼(me)需求。
這(zhè)時,我們可以用一個專門的聊天機器人跟他進(jìn)行對(duì)話,用GPT的對(duì)話能(néng)力把客戶的需求問清楚。當然,也開(kāi)始人機協同,由人類顧問用GPT作爲輔助,跟客戶對(duì)話詢問需求。
我們知道(dào),GPT有分析和推理的能(néng)力,有了客戶需求之後(hòu),我們可讓GPT去進(jìn)行分析、將(jiāng)旅遊行程設計的大任務拆成(chéng)一一系列任務,分别去在内部、外部進(jìn)行查詢,比如去外部查詢機票酒店等信息。
之後(hòu),我們再運用GPT的文字能(néng)力,請它將(jiāng)收集到的資料整合成(chéng)一個提案。這(zhè)時,我們就可以把提案拿給客戶看,如果客戶對(duì)某個旅遊環節設計不滿意,我們再把這(zhè)個流程走一遍直到客戶滿意。最終,我們再將(jiāng)GPT 與比如排版工具、預定工具等聯合使用,幫客戶預定酒店、機票、各地的車輛與導遊等,同時生成(chéng)詳盡的最終方案手冊給到客戶。
要注意的是,在這(zhè)樣(yàng)的場景裡(lǐ),并不是全部交給大模型就可以了,要靠人類專業人士來有效地運用,我們才能(néng)用 GPT 來提升企業服務客戶的能(néng)力。
③ 進(jìn)階使用
目前還(hái)處在大模型廣泛應用的初期,但有些進(jìn)階使用的方向(xiàng)已經(jīng)被(bèi)證明是必需的,衆多的技術團隊和企業在嘗試著(zhe)。
第一種(zhǒng),使用微調模型。經(jīng)預訓練的大模型一開(kāi)始是不懂行業中的專有知識,我們可以通過(guò)指令微調訓練來形成(chéng)适合本行業、本企業的模型,用它來服務客戶。
企業會考慮微調訓練出自己的模型,而不是采用公開(kāi)的模型服務,也是因爲考慮到數據問題,一方面(miàn)數據是企業的關鍵資産,你不願與其他企業分享,另一方面(miàn)數據也涉及到可能(néng)客戶隐私,企業不能(néng)與其他人分享。
第二種(zhǒng),爲模型外挂知識庫。現在不少AI 面(miàn)向(xiàng)C端的産品做法是,用公開(kāi)的模型服務或自己的微調模型,但又額外附加一個知識庫,當用戶提問或提出要求時,應用會先去知識庫進(jìn)行匹配,然後(hòu)將(jiāng)匹配出來的信息交由GPT處理。
這(zhè)說起(qǐ)來容易,實踐中出好(hǎo)的效果還(hái)是很難的。通常來說難點主要有兩(liǎng)個方面(miàn):第一,怎麼(me)把自己本來雜亂的數據變成(chéng)可以讓GPT理解的數據。第二,GPT的性能(néng)(即回答的質量)究竟能(néng)拿到多少分,能(néng)否滿足用戶的需求。
這(zhè)裡(lǐ)有很多工程上的具體實踐,也有很多研究者的巧思。比如,用戶問了問題,我們用問題在知識庫做相關性匹配時,匹配不出想要的資料怎麼(me)辦?去年底有一篇論文提出的做法(HyDE)已經(jīng)變成(chéng)了行業的普遍實踐。
它的做法是,我們可以拿問題先去問GPT,得到一個(可能(néng)質量不佳的)假設性回答,然後(hòu)我們拿這(zhè)個假設性回答去知識庫進(jìn)行匹配,就可以匹配出更相關的資料。

之後(hòu),再拿著(zhe)這(zhè)些資料去問GPT,這(zhè)時可以得到好(hǎo)得多回答。這(zhè)個回答的效果與針對(duì)一個細分領域、對(duì)模型進(jìn)行相對(duì)要複雜一些的微調得到的結果是相當的。總的來說,GPT等大語言模型的研發(fā)和應用都(dōu)欣欣向(xiàng)榮,但目前所有人都(dōu)在努力地進(jìn)行各種(zhǒng)嘗試,既有研究上的嘗試,也有工程上的嘗試,也有應用上的嘗試。
今天,我們處在一個的新範式轉移中,海量的知識被(bèi)壓縮進(jìn)了模型,讓得知識随手可及。我們每個人、每個企業都(dōu)有了一個擁有強大的知識與能(néng)力的機器助手。
現在,每個人都(dōu)應該去了解生成(chéng)式AI,理解它真正的用途,然後(hòu)從你自己的角度切入進(jìn)去。
這(zhè)是我今天的分享,謝謝大家。
标簽: AI
版權申明:本站文章部分自網絡,如有侵權,請聯系:hezuo@lyzg168.com
特别注意:本站所有轉載文章言論不代表本站觀點,本站所提供的攝影照片,插畫,設計作品,如需使用,請與原作者聯系,版權歸原作者所有
輸入您的聯系信息,我們將(jiāng)盡快和你取得聯系!
Tel:15137991270
企業QQ:210603461
Emile:hezuo@lyzg168.com
地址:洛陽市西工區王城大道(dào)221号富雅東方B座1711室
網站:https://www.lyzg168.com

我們的微信
關注兆光,了解我們的服務與最新資訊。
Copyright © 2018-2019 洛陽霆雲網絡科技有限公司
