作者: 兆光科技 發(fā)布時間: 2024/08/08 點擊: 4712次
隻需12秒,隻憑手機自己的算力,就能(néng)拿Stable Diffusion生成(chéng)一張圖像。
而且是完成(chéng)了20次叠代的那種(zhǒng)。

要知道(dào),現在的擴散模型基本都(dōu)超過(guò)了10億參數,想要快速生成(chéng)一張圖片,要麼(me)基于雲計算,要麼(me)就是要本地硬件夠強大了。
而随著(zhe)大模型應用逐漸普及開(kāi)來,在個人電腦、手機上跑大模型很可能(néng)是未來的新趨勢。
由此,谷歌的研究員們帶來了這(zhè)篇新成(chéng)果,名字就叫(jiào)Speed is all you need:通過(guò)GPU優化加速大規模擴散模型在設備上的推理速度。

該方法是針對(duì)Stable Diffusion來做的優化,但同時也能(néng)适應其他擴散模型。面(miàn)向(xiàng)的任務是從文本生成(chéng)圖像。
具體優化可以分成(chéng)三個部分:
設計專門的内核
提升Attention模型效率
Winograd卷積加速
首先來看專門設計的内核,它包括了組歸一化和GELU激活函數。
組歸一化是在整個UNet體系結構中實現,這(zhè)種(zhǒng)歸一化的工作原理是將(jiāng)特征映射的通道(dào)劃分爲更小的組,并對(duì)每個組獨立歸一,使組歸一化較少依賴于批大小,并且能(néng)适應更大範圍的批處理大小和網絡架構。
研究人員以GPU著(zhe)色器(shader)的形式設計了一個獨特的核,能(néng)在沒(méi)有任何中間張量的情況下,在單個GPU命令中執行所有内核。
GELU激活函數中,包含大量的數值計算,如懲罰、高斯誤差函數等。
通過(guò)一個專用著(zhe)色器來整合這(zhè)些數值計算以及伴随的分割和乘法操作,使得這(zhè)些計算能(néng)放在一個簡單的draw call裡(lǐ)。
Draw call是CPU調用圖像編程接口,命令GPU進(jìn)行渲染的操作。
接下來,到了提升Attention模型效率方面(miàn),論文介紹了兩(liǎng)種(zhǒng)優化方法。
其一是部分融合softmax函數。
爲了避免在大矩陣A上執行整個softmax計算,該研究設計了一個GPU著(zhe)色器來計算L和S向(xiàng)量以減少計算,最終得到一個大小爲N×2的張量。然後(hòu)將(jiāng)softmax計算和矩陣V的矩陣乘法融合。
這(zhè)種(zhǒng)方法大幅減少了中間程序的内存占用張量和總體延遲。
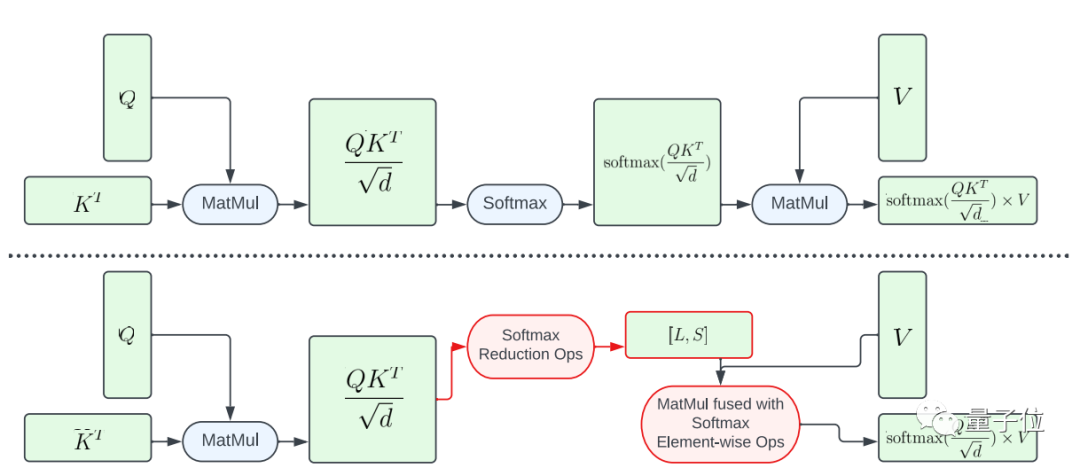
需要強調的是從A到L、S的計算映射的并行是有限的,因爲結果張量中的元素比輸入張量A中的元素數量要少得多。
爲了增加并行、進(jìn)一步降低延遲,該研究將(jiāng)A中的元素組成(chéng)block,將(jiāng)歸約操作(reduction operations)切分爲多個部分進(jìn)行。
然後(hòu)在每個block上執行計算,然後(hòu)將(jiāng)其簡化爲最終結果。
利用精心設計的線程和内存緩存管理,可以在多個部分實現使用單個GPU命令降低延遲。
另一種(zhǒng)優化方法是FlashAttention。
這(zhè)是去年火起(qǐ)來的IO感知精确注意力算法,具體有兩(liǎng)種(zhǒng)加速技術:按塊遞增計算即平鋪、并在後(hòu)向(xiàng)傳遞中重新計算注意力,將(jiāng)所有注意力操作融合到CUDA内核中。
相較于标準Attention,這(zhè)種(zhǒng)方法能(néng)減少HBM(高帶寬内存)訪問,提高整體效率。
不過(guò)FlashAttention内核的緩存器密集度非常高(register-intensive),所以該團隊是有選擇性地使用這(zhè)一優化方法。
他們在注意力矩陣d=40的Adreno GPU和Apple GPU上使用FlashAttention,其他情況下使用部分融合softmax函數。
第三部分是Winograd卷積加速。
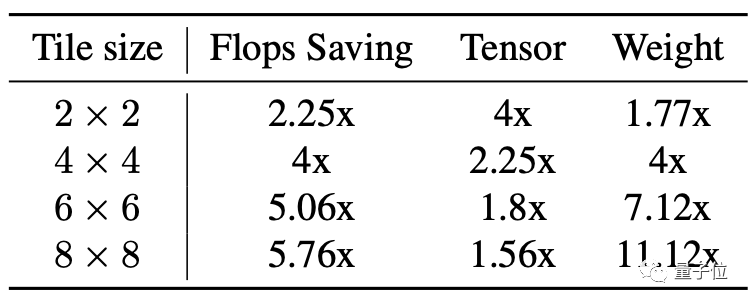
它的原理簡單來說就是使用更多的加法計算來減少乘法計算,從而降低計算量。
但弊端也很明顯,將(jiāng)會帶來更多的顯存消耗和數值錯誤,尤其是在tile比較大的情況時。
Stable Diffusion的主幹非常依賴3×3卷積層,尤其是在圖像解碼器方面(miàn),這(zhè)裡(lǐ)90%的層都(dōu)是由3×3卷積層構成(chéng)的。
研究人員分析後(hòu)發(fā)現,在使用4×4大小的tile時,是模型計算效率和顯存利用率的最佳平衡點。
爲了評估提升效果,研究人員先在手機上進(jìn)行了基準測試。
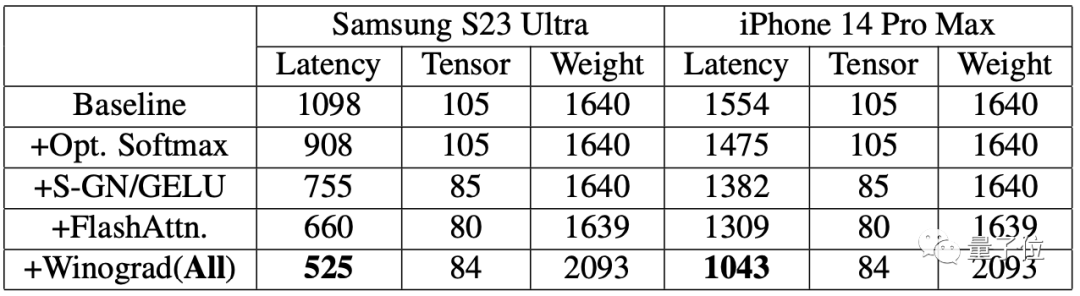
結果表明,兩(liǎng)部手機在使用了加速算法後(hòu),生成(chéng)圖片的速度都(dōu)明顯提升。
其中三星S23 Ultra的延遲降低了52.2%,iPhone 14 Pro Max上的延遲降低了32.9%。
在三星S23 Ultra上端到端從文本生成(chéng)一張512×512像素的圖片,叠代20次,耗時在12秒以内。
标簽: AI
版權申明:本站文章部分自網絡,如有侵權,請聯系:hezuo@lyzg168.com
特别注意:本站所有轉載文章言論不代表本站觀點,本站所提供的攝影照片,插畫,設計作品,如需使用,請與原作者聯系,版權歸原作者所有
輸入您的聯系信息,我們將(jiāng)盡快和你取得聯系!
Tel:15137991270
企業QQ:210603461
Emile:hezuo@lyzg168.com
地址:洛陽市西工區王城大道(dào)221号富雅東方B座1711室
網站:https://www.lyzg168.com

我們的微信
關注兆光,了解我們的服務與最新資訊。
Copyright © 2018-2019 洛陽霆雲網絡科技有限公司
