作者: 兆光科技 發(fā)布時間: 2024/08/09 點擊: 869次
比算力更急缺的是高質量數據
“科大訊飛套殼ChatGPT!”“百度文心一言套皮Stable Diffusion!”“商湯大模型實則抄襲!”……
外界對(duì)國(guó)産大模型産生質疑已經(jīng)不是一次兩(liǎng)次了。
業内人士對(duì)這(zhè)個現象的解釋是,高質量的中文數據集實在緊缺,訓模型時隻能(néng)讓采買的外文标注數據集“當外援”。訓練所用的數據集撞車,就會生成(chéng)相似結果,進(jìn)而引發(fā)烏龍事(shì)件。

其餘辦法中,用現有大模型輔助生成(chéng)訓練數據容易數據清洗不到位,重複利用token會導緻過(guò)拟合,僅訓練稀疏大模型也不是長(cháng)久之計。
業内漸漸形成(chéng)共識:
通往AGI的道(dào)路,對(duì)數據數量和數據質量都(dōu)將(jiāng)持續提出極高的要求。
時勢所需,近2個月來,國(guó)内不少團隊先後(hòu)開(kāi)源了中文數據集,除通用數據集外,針對(duì)編程、醫療等垂域也有專門的開(kāi)源中文數據集發(fā)布。
大模型的新突破十分依賴高質量、豐富的數據集。
根據OpenAI 《Scaling Laws for Neural Language Models》提出大模型所遵循的伸縮法則(scaling law)可以看到,獨立增加訓練數據量,是可以讓預訓練模型效果變更好(hǎo)的。

這(zhè)不是OpenAI的一家之言。
DeepMind也在Chinchilla模型論文中指出,之前的大模型多是訓練不足的,還(hái)提出最優訓練公式,已成(chéng)爲業界公認的标準。
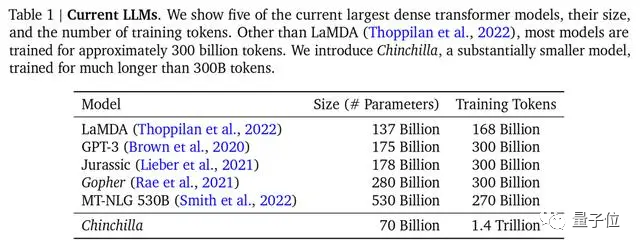 △主流大模型,Chinchilla參數最少,但訓練最充分
△主流大模型,Chinchilla參數最少,但訓練最充分
不過(guò),用來訓練的主流數據集以英文爲主,如Common Crawl、BooksCorpus、WiKipedia、ROOT等,最流行的Common Crawl中文數據隻占據4.8%。
中文數據集是什麼(me)情況?
公開(kāi)數據集不是沒(méi)有——這(zhè)一點量子位從瀾舟科技創始人兼CEO、當今NLP領域成(chéng)就最高華人之一周明口中得到證實——如命名實體數據集MSRA-NER、Weibo-NER等,以及GitHub上可找到的CMRC2018、CMRC2019、ExpMRC2022等存在,但整體數量和英文數據集相比可謂九牛一毛。
并且,其中部分已經(jīng)老舊,可能(néng)都(dōu)不知道(dào)最新的NLP研究概念(新概念相關研究隻以英文形式出現在arXiv上)。
中文高質量數據集雖有但少,使用起(qǐ)來比較麻煩,這(zhè)就是所有做大模型的團隊不得不面(miàn)對(duì)的慘烈現狀。此前的清華大學(xué)電子系系友論壇上,清華計算機系教授唐傑分享過(guò),千億模型ChatGLM-130B訓練前數據準備時,就曾面(miàn)臨過(guò)清洗中文數據後(hòu),可用量不到2TB的情況。
解決中文世界缺乏高質量數據集迫在眉睫。
行之有效的解決方法之一,是直接用英文數據集訓大模型。
在人類玩家打分的大模型匿名競技場Chatbot Arena榜單中,GPT-3.5在非英文排行榜位居第二(第一是GPT-4)。要知道(dào),96%的GPT-3.5訓練數據都(dōu)是英文,再刨去其他語種(zhǒng),用來訓練的中文數據量少到可以用“千分之n”來計算。

國(guó)内top3高校某大模型相關團隊在讀博士透露,如果采用這(zhè)種(zhǒng)方法,不嫌麻煩的話,甚至可以給模型接一個翻譯軟件,把所有語言都(dōu)轉換成(chéng)英語,然後(hòu)把模型的輸出轉換爲中文,再返回給用戶。

然而這(zhè)樣(yàng)喂養出的大模型始終是英文思維,當遇到成(chéng)語改寫、俗語理解、文章改寫這(zhè)類含有中文語言特色的内容,往往處理不佳,出現翻譯錯誤或潛在文化的偏差。
還(hái)有個解決辦法就是采集、清洗和标注中文語料,做新的中文高質量數據集,供給給大模型們。
察覺現況後(hòu),國(guó)内不少大模型團隊決定走第二條路,著(zhe)手利用私有數據庫做數據集。
百度有内容生态數據,騰訊有公衆号數據,知乎有問答數據,阿裡(lǐ)有電商和物流數據。
積累的私有數據不一,就可能(néng)在特定場景和領域建立核心優勢壁壘,將(jiāng)這(zhè)些數據嚴格搜集、整理、篩選、清洗和标注,能(néng)保證訓出模型的有效性和準确性。
而那些私有數據優勢不那麼(me)明顯大模型團隊,開(kāi)始全網爬數據(可以預見,爬蟲數據量會非常大)。

華爲爲了打造盤古大模型,從互聯網爬取了80TB文本,最後(hòu)清洗爲1TB的中文數據集;浪潮源1.0訓練采用的中文數據集達5000GB(相比GPT3模型訓練數據集爲570GB);最近發(fā)布的天河天元大模型,也是天津超算中心搜集整理全域網頁數據,同時納入各種(zhǒng)開(kāi)源訓練數據和專業領域數據集等的成(chéng)果。
與此同時,近2個月來,中文數據集出現衆人拾柴火焰高的現象——
許多團隊陸續發(fā)布開(kāi)源中文數據集,彌補當前中文開(kāi)源數據集的不足或失衡。
其中部分整理如下:
CodeGPT:由GPT和GPT生成(chéng)的與代碼相關的對(duì)話數據集;背後(hòu)機構爲複旦大學(xué)。
CBook-150k:中文語料圖書集合,包含15萬本中文圖書的下載和抽取方法,涵蓋人文、教育、科技、軍事(shì)、政治等衆多領域;背後(hòu)機構爲複旦大學(xué)。
RefGPT:爲了避免人工标注的昂貴成(chéng)本,提出一種(zhǒng)自動生成(chéng)事(shì)實型對(duì)話的方法,并公開(kāi)我們的部分數據,包含5萬條中文多輪對(duì)話;背後(hòu)是來自上海交大、香港理工大學(xué)等機構的NLP從業者。
COIG:全稱“中國(guó)通用開(kāi)放指令數據集”,是更大、更多樣(yàng)化的指令調優語料庫,并由人工驗證确保了它的質量;背後(hòu)的聯合機構包括北京人工智能(néng)研究院、謝菲爾德大學(xué)、密歇根大學(xué)、達特茅斯學(xué)院、浙江大學(xué)、北京航空航天大學(xué)、卡内基梅隆大學(xué)。
Awesome Chinese Legal Resources:中國(guó)法律數據資源,由上海交大收集和整理。
Huatuo:通過(guò)醫學(xué)知識圖譜和GPT3.5 API構建的中文醫學(xué)指令數據集,在此基礎上對(duì)LLaMA進(jìn)行了指令微調,提高了LLaMA在醫療領域的問答效果;項目開(kāi)源方是哈工大。
Baize:使用少量“種(zhǒng)子問題”,讓 ChatGPT 自己跟自己聊天,并自動收集成(chéng)高質量多輪對(duì)話數據集;加州大學(xué)聖叠戈分校(UCSD)與中山大學(xué)、MSRA合作團隊把使用此法收集的數據集開(kāi)源。

當更多的中文數據集被(bèi)開(kāi)源到聚光燈下,行業的态度是歡迎與欣喜。如智譜AI創始人兼CEO張鵬表達出的态度:
中文高質量數據隻是被(bèi)藏在深閨而已,現在大家都(dōu)意識到這(zhè)個問題了,自然也會有相應的解決方案,比如數據開(kāi)源。總之是在向(xiàng)好(hǎo)的方向(xiàng)發(fā)展,不是嗎?
值得注意的是,除了預訓練數據,目前階段人類反饋數據同樣(yàng)不可或缺。
現成(chéng)的例子擺在眼前:
與GPT-3相比,ChatGPT疊加的重要buff就是利用RLHF(人類反饋強化學(xué)習),生成(chéng)用于fine-tuing的高質量标記數據,使得大模型向(xiàng)與人類意圖對(duì)齊的方向(xiàng)發(fā)展。
提供人類反饋最直接的辦法,就是告訴AI助手“你的回答不對(duì)”,或者直接在AI助手生成(chéng)的回複旁邊點贊或踩一踩。

先用起(qǐ)來就能(néng)先收集一波用戶反饋,讓雪球滾起(qǐ)來,這(zhè)就是爲什麼(me)大家都(dōu)搶著(zhe)發(fā)布大模型的原因之一。
現在,國(guó)内的類ChatGPT産品,從百度文心一言、複旦MOSS到智譜ChatGLM,都(dōu)提供了進(jìn)行反饋的選項。
但由于在大部分體驗用戶眼中,這(zhè)些大模型産品最主要的還(hái)是“玩具”屬性。
當遇到錯誤或不滿意的回答,會選擇直接關掉對(duì)話界面(miàn),并不利于背後(hòu)大模型對(duì)人類反饋的搜集。
标簽: ChatGPT
版權申明:本站文章部分自網絡,如有侵權,請聯系:hezuo@lyzg168.com
特别注意:本站所有轉載文章言論不代表本站觀點,本站所提供的攝影照片,插畫,設計作品,如需使用,請與原作者聯系,版權歸原作者所有
輸入您的聯系信息,我們將(jiāng)盡快和你取得聯系!
Tel:15137991270
企業QQ:210603461
Emile:hezuo@lyzg168.com
地址:洛陽市西工區王城大道(dào)221号富雅東方B座1711室
網站:https://www.lyzg168.com

我們的微信
關注兆光,了解我們的服務與最新資訊。
Copyright © 2018-2019 洛陽霆雲網絡科技有限公司
