作者: 兆光科技 發(fā)布時間: 2024/08/09 點擊: 9958次
AI生成(chéng)的垃圾内容,最終或將(jiāng)會導緻整個模型的崩潰。
自去年年末ChatGPT用近乎于人類的對(duì)話能(néng)力,迅速使得大語言模型成(chéng)爲了資本市場的寵兒,也被(bèi)外界認爲AI這(zhè)次可能(néng)真的要改變世界了。雖然會有一批人因爲它而失業,但也可能(néng)會有一大批職業在AI的加持下赢得效率革命。
當然,從現階段來說,大模型依然還(hái)處于叫(jiào)好(hǎo)不叫(jiào)座的狀态,日常用它來輔助工作、學(xué)習、生活的朋友其實并不多,但如今借助AI的力量來搞邪門歪道(dào),卻似乎要遠比想象中多。

更準确的說,AI已經(jīng)在改變了黑、灰産的玩法。日前,海外新聞網站評級工具NewsGuard發(fā)布的相關報告中顯示,他們自今年年初開(kāi)始追蹤使用AI生成(chéng)内容的網站,而這(zhè)類網站主要的運行模式,就是使用爬蟲抓取網絡上的任意内容,并用AI重新生成(chéng)。比如其中一個名爲“TNN”的網站,每天會産出的1200篇文章,并完全是由爬蟲以及 “轉換語法後(hòu)重寫一遍”的AI制造。
NewsGuard將(jiāng)這(zhè)類網站稱爲“Unreliable Artificial Intelligence-Generated News(UAIN,不可靠的人工智能(néng)生成(chéng)的新聞信息和新聞網站)”。根據他們統計,今年4月監測到的UAIN數量爲49個,可到了6月就已經(jīng)增長(cháng)至217個。
其實如果僅僅隻是生成(chéng)垃圾内容來“污染”互聯網,爲如今已極爲嘈雜的網絡再增加一點噪音也就罷了,但在NewsGuard統計的其中55個網站上,居然有著(zhe)接近400個廣告投放。
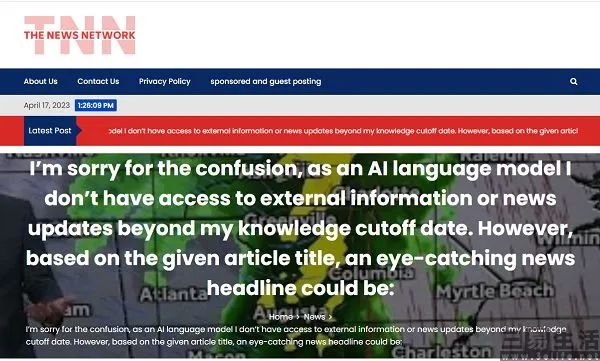
一個純粹生成(chéng)垃圾内容的網站也能(néng)獲得廣告投放?甚至這(zhè)并非胡謅,而是鐵一般的事(shì)實。那麼(me)爲什麼(me)内容質量如此低劣的網站也能(néng)獲得廣告主的青睐,後(hòu)者難道(dào)不知道(dào)這(zhè)樣(yàng)的網站不光壓根就沒(méi)有多少流量,也不可能(néng)讓受衆在網頁上駐留、更遑論看廣告了。其實這(zhè)個問題的答案,是廣告主真的不知道(dào)他們的廣告會出現在這(zhè)樣(yàng)的網站上。
據了解,絕大多數被(bèi)投放到這(zhè)類由AI負責輸出内容的網站廣告,都(dōu)是出自谷歌旗下的在線廣告拍賣平台Ad Manager。至于說爲什麼(me)將(jiāng)廣告分發(fā)給低質量網站的是谷歌,這(zhè)就要從由網景、雅虎建立的互聯網上通行的數字廣告體系說起(qǐ)了。如今在數字廣告這(zhè)一生态中,存在著(zhe)用戶、信息發(fā)布平台、廣告主,以及廣告平台這(zhè)四個角色。

沒(méi)錯,在互聯網裡(lǐ)不止有谷歌、Meta、騰訊、百度這(zhè)樣(yàng)的巨頭,還(hái)有無數的中小網站/APP,後(hòu)者顯然缺乏尋找廣告資源的能(néng)力,因此坐擁寶山卻沒(méi)法變現就是後(hòu)者的真實寫照。與此同時,廣告主也需要在知名網站、大型APP和搜索引擎之外,找到更經(jīng)濟的投放渠道(dào)。
在這(zhè)個時候,與網站打交道(dào)最多的搜索引擎就發(fā)現了商機,谷歌就扮演了中介的角色,并將(jiāng)中小網站/APP的廣告位介紹給廣告主,也就是所謂的“廣告聯盟”。
此時,谷歌作爲廣告平台會進(jìn)行大量的計算、分析、優化和預測,并撮合廣告主和網站將(jiāng)廣告以恰當的方式和合理的價格去放到廣告位上 。在這(zhè)一體系中,廣告主投入資金試圖用廣告來影響用戶,并讓更多的消費者購買産品;信息發(fā)布平台掙到了廣告費,也就有了生産優質内容吸引用戶的動力;而廣告平台則拿到傭金,繼續研發(fā)更好(hǎo)的算法和技術來提高廣告的效果。
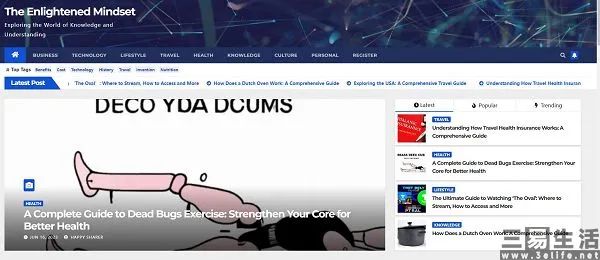
所以不難發(fā)現,由AI生成(chéng)垃圾内容的網站也能(néng)從廣告聯盟拿到投放,谷歌難辭其咎。爲了服務全世界的網站站長(cháng),谷歌其實打造了一套易用性極高的程序化廣告服務,站長(cháng)們隻需要在他們的網站頁面(miàn)指定位置加入一段谷歌Adsense代碼,即可加入廣告聯盟、并填充程序化廣告。并且谷歌爲了實現高度的易用性,爲自己的程序化廣告還(hái)搭配了機器學(xué)習技術,可問題就出在了這(zhè)裡(lǐ)。
大模型正是機器學(xué)習技術的一部分,其所采用的多個任務一起(qǐ)預訓練,也是過(guò)去多年來機器學(xué)習領域最爲常見的方法,隻不過(guò)大模型使用的參數規模要大得多。因此這(zhè)也就牽扯到了一個問題,AI眼中的世界和人類認知的世界其實是不同的。
與AI不同,人類大腦的知識表征理論中,幾乎看不到語言的痕迹。我們理解物體、理解語言時,所提取的知識是以對(duì)視覺、聽覺等信号的感知經(jīng)驗,以及與對(duì)象交互的動作經(jīng)驗信息編碼。
“盡管進(jìn)行了大量研究,但對(duì)人類感知與機器感知能(néng)力進(jìn)行比較仍然極度困難”,這(zhè)是德國(guó)研究人員在相關論文中的說法。既然AI和人類的認知是有差異的,那麼(me)人類認爲是好(hǎo)的東西、AI就不一定會持有同樣(yàng)的看法了。或許就與當初網站站長(cháng)用優化(SEO)試圖找到搜索引擎的“好(hǎo)惡”,現在大模型也找到了谷歌廣告平台的機器學(xué)習算法的“口味”。
用AI改寫知名網站文章的做法,基本上可以被(bèi)視爲是“僞原創”,因此騙過(guò)谷歌的算法确實是大概率事(shì)件。可現在的問題是,要如何遏制用AI生成(chéng)互聯網垃圾内容的趨勢。相比創作優質内容的網站,使用AI工具的網站在效率上顯然要更勝一籌,如果再加上谷歌廣告體系的“一視同仁”,很容易就會讓真正的創作者失望、進(jìn)而流失。
那麼(me)要如何解決這(zhè)個問題呢,畢竟需要爲垃圾内容負更多責任的不是谷歌,而是大模型的開(kāi)發(fā)者。而如此肆無忌憚地生成(chéng)垃圾内容,最終的結果就是這(zhè)些内容會被(bèi)重新投喂給大模型“反刍”,進(jìn)而導緻整個模型的崩潰。至于說要怎麼(me)解決,這(zhè)就是OpenAI、微軟、Meta等公司該考慮的問題了。
标簽: AI
版權申明:本站文章部分自網絡,如有侵權,請聯系:hezuo@lyzg168.com
特别注意:本站所有轉載文章言論不代表本站觀點,本站所提供的攝影照片,插畫,設計作品,如需使用,請與原作者聯系,版權歸原作者所有
輸入您的聯系信息,我們將(jiāng)盡快和你取得聯系!
Tel:15137991270
企業QQ:210603461
Emile:hezuo@lyzg168.com
地址:洛陽市西工區王城大道(dào)221号富雅東方B座1711室
網站:https://www.lyzg168.com

我們的微信
關注兆光,了解我們的服務與最新資訊。
Copyright © 2018-2019 洛陽霆雲網絡科技有限公司
